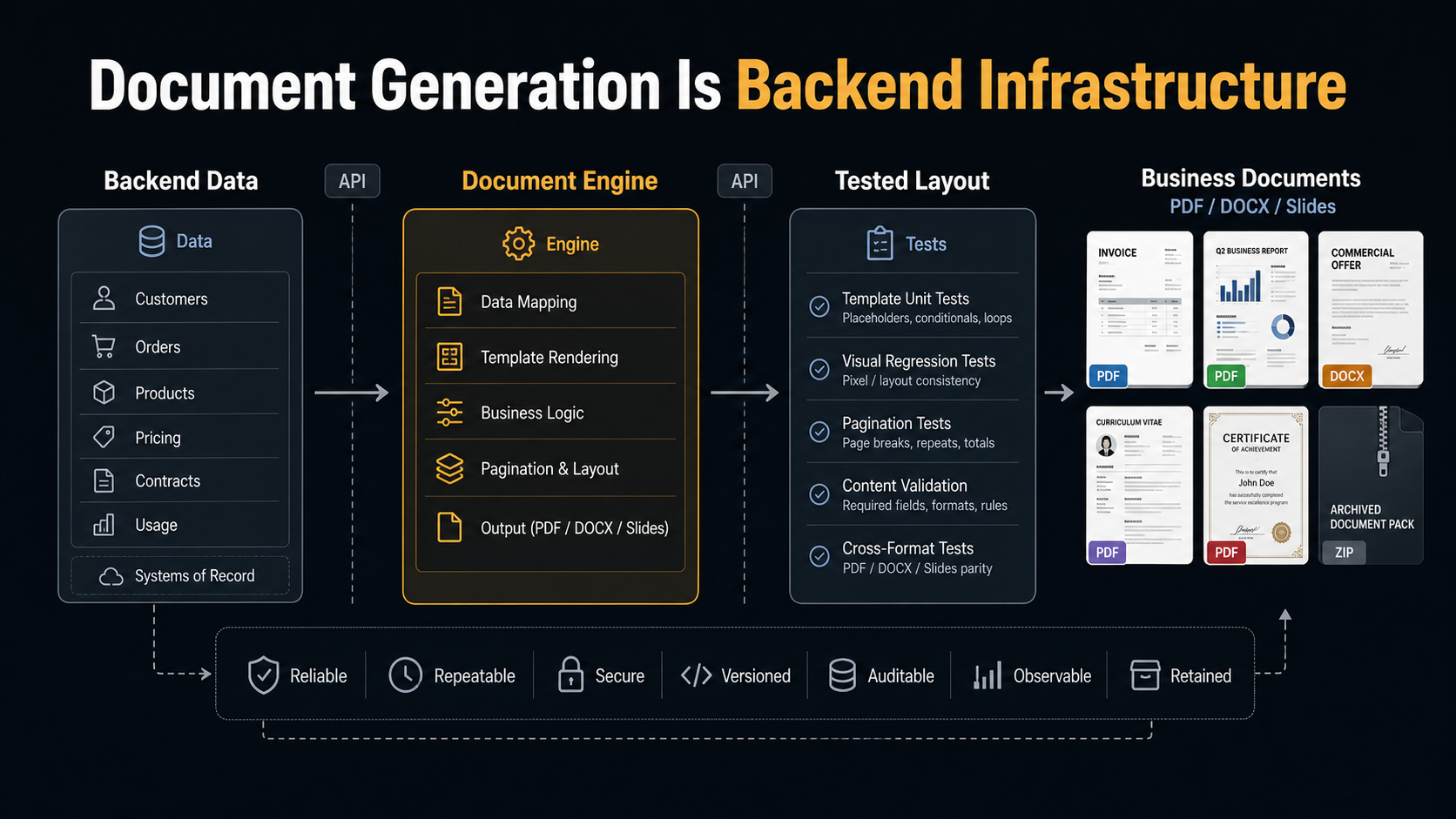
Most backend systems eventually need to produce documents: invoices, reports, offers, letters, CVs, certificates, export packs. The business treats those documents as serious output. They are sent to customers, attached to applications, used by operations teams, and archived for compliance.
The code that produces them often does not get the same respect.
This is the companion to What Drove Me to Build GraphCompose — that post was the personal story of how GraphCompose started. This one is about a claim I now believe after living inside that code: document generation is backend infrastructure, and it pays off when you build it like infrastructure instead of like a one-off script.
Documents are not decoration
A generated PDF is often the actual product of a flow, not a cosmetic detail. If it is wrong, the customer sees it, the application is rejected, or the compliance archive is incorrect.
That changes how the code should be treated. A document engine needs clear APIs, predictable output, versionable templates, and tests. It needs to be boring in the best way: understandable, repeatable, and safe to evolve. The moment a document is business-critical, the code that draws it is infrastructure, whether you planned it that way or not.
The usual failure mode
PDF generation in Java can become a long sequence of coordinates, drawing calls, conditionals, and layout patches. A small content change breaks spacing. A new section disturbs pagination. A template looks fine in one data case and fails in another.
Treated as a throwaway script, document code rots like any other untested path — except the breakage ships straight to a customer. The cost is hidden until the data stops being polite.
When you actually need a document engine
You do not always need one, and pretending otherwise is how libraries get overused. Be honest about the small cases:
- One fixed PDF that rarely changes, with simple data: a direct PDFBox or iText script is fine.
- A single label, a receipt line, a one-off export: do not pull in an engine for it.
You start needing a real engine when the problem stops being a single document and becomes a system of documents:
- the same visual language repeats across several document types (CV, cover letter, invoice, proposal)
- the data is variable in size — one row or one hundred rows, a short name or a very long one
- templates change often and must stay reviewable by another developer
- the output is business-critical and must be testable, not just “looked right last time”
- you may need another output format later (PDF now, maybe DOCX or slides) without rewriting every template
That is the line where ad-hoc drawing code stops scaling and infrastructure starts paying for itself.
Why declarative
Backend developers already understand declarative ideas from SQL, Spring configuration, validation rules, and build files. You describe what should exist, and the engine handles the mechanics.
GraphCompose applies that style to documents. Instead of making the template responsible for every drawing step, the template defines the document model and layout rules: sections, blocks, spacing, typography, hierarchy, and reusable components. The engine handles measurement, pagination, rendering, and repeatable behavior.
That separation matters because document templates change constantly. A declarative template is easier to review, easier to refactor, and easier to explain than a wall of coordinates. Rendering should still be precise, but precision should not require every template author to think in raw pixels.
Infrastructure means testable
A document engine only earns the word “infrastructure” if you can trust it under change.
That takes more than one shape of test: small checks for layout calculations, regression tests for document structure, rendered-output checks for visual behavior, and real templates that act as integration examples. The goal is not to test pixels for their own sake — it is to catch the kind of change that would make a business document look broken or untrustworthy. I wrote more about that engineering side in Lessons from Building a Java PDF Engine.
The trade-off I wanted
Building a document engine is a good reminder that “simple API” does not mean “simple implementation.” Layout, pagination, typography, and rendering all contain edge cases, and the engine is where they have to be solved.
The work is worth it because every hard decision inside the engine removes complexity from application code. That is the trade-off I was after: keep the hard parts in one focused library, so product code can describe documents clearly and the rest of the backend can stop fighting coordinates.
Documents are infrastructure. It is easier to admit that early than to discover it the day a template breaks in production.